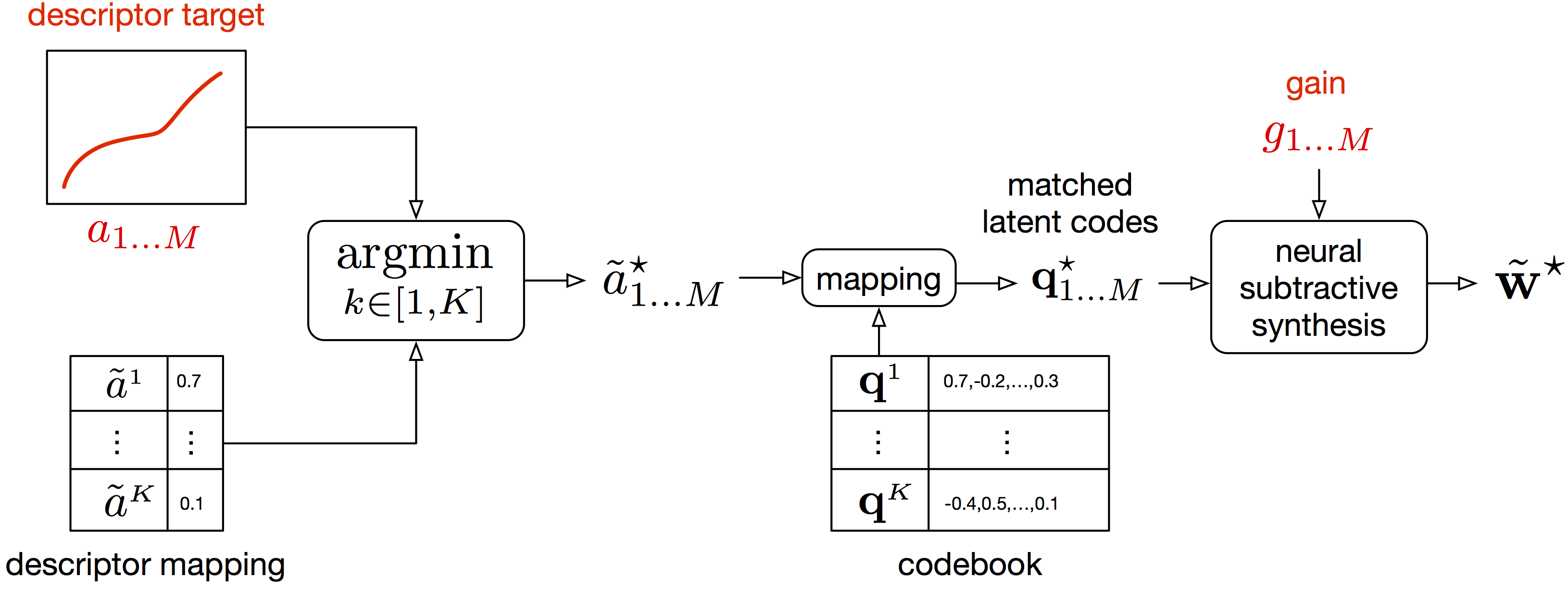
Vector-Quantized Timbre Representation
Demonstration materials, paper available at https://arxiv.org/abs/2007.06349.
Details of the mapping method for descriptor-based synthesis
Following the notations from the paper, we detail the procedure for mapping the discrete latent space with a signal descriptor. For instance acoustic properties such as centroid, bandwidth or fundamental frequency. And then using this mapping to control synthesis with a descriptor target. We call this descriptor-based synthesis, which is done without iterative search but with direct selection of the best matching latent features. The operator that we call descriptor can be any signal descriptors, we use the spectral features implemented in librosa. Fundamental frequency estimate is computed with the PyWorldVocoder.

The mapping is performed with the following analysis.
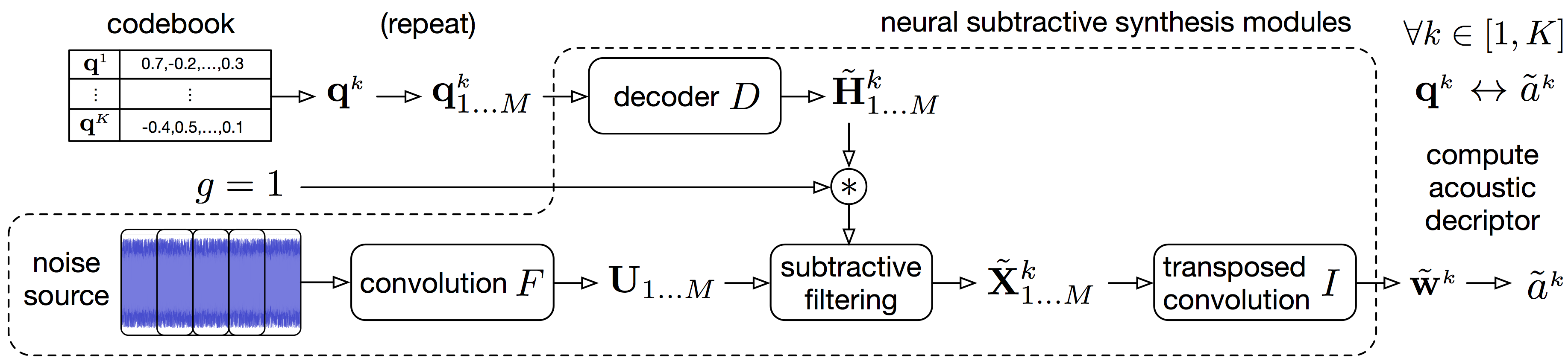
Descriptor-based synthesis can be done using the mapping to a given acoustic descriptor target. Red denotes the controllable synthesis parameters.
Timbre transfer
The model can be used for timbre transfer from diverse sources, including non-musical sounds such as vocal imitations, to an invidual timbre. It learns a discrete representation of the trained timbre, a latent codebook into which any encoder outputs is matched. For instance, an input audio of a clarinet performance can be quantized into latent features learned from a violin dataset. Subsequently, the decoder synthesizes an audio that is the closest match to the input given the target timbre features.
![]()
Audio samples from the models
One VQ-VAE model has been trained per individual timbre domain. The corresponding datasets are either isolated instrument performances from multitrack recordings (URMP, Phenicx) or singing voice (subset of VocalSet). The instruments of the orchestra are: basson, cello, clarinet, double-bass, flute, horn, oboe, trumpet, viola and violin.
Descriptor-based synthesis
To demonstrate to possiblity to control synthesis from some acoustic descriptor targets, we analyze the VQ-VAE discrete latent space and traverse the latent codes in an increasing order with respect to different descriptors. As explained in the upper details, we can use the sorted codebook to map with some user-defined descriptor targets. We provide the sound output as well as the descriptor curve and spectrogam that have been synthesized.
| bandwidth in cello | |
|---|---|
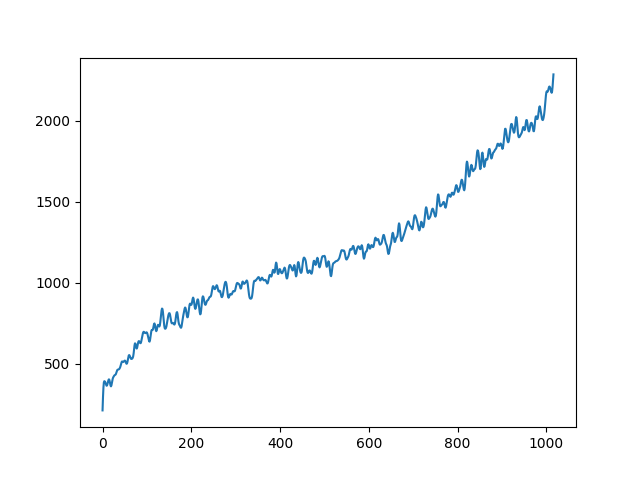 |
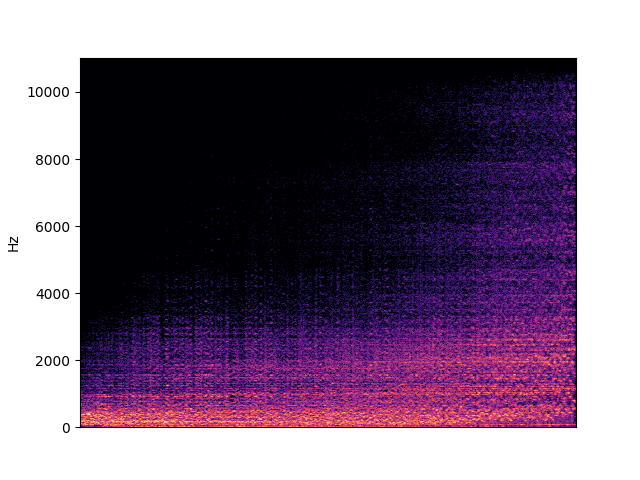 |
| fundamental in singing (female only) | |
|---|---|
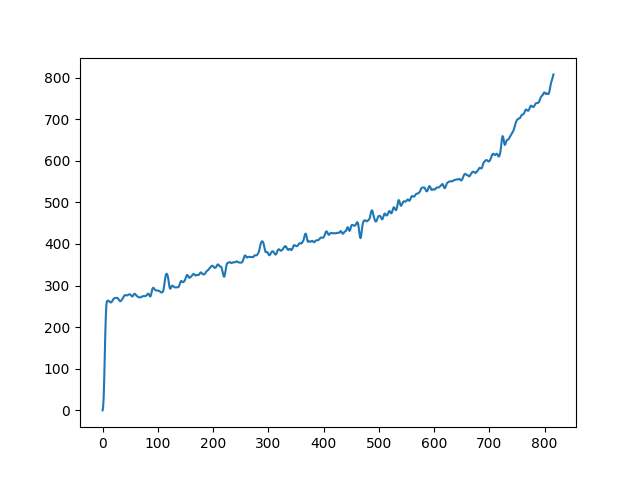 |
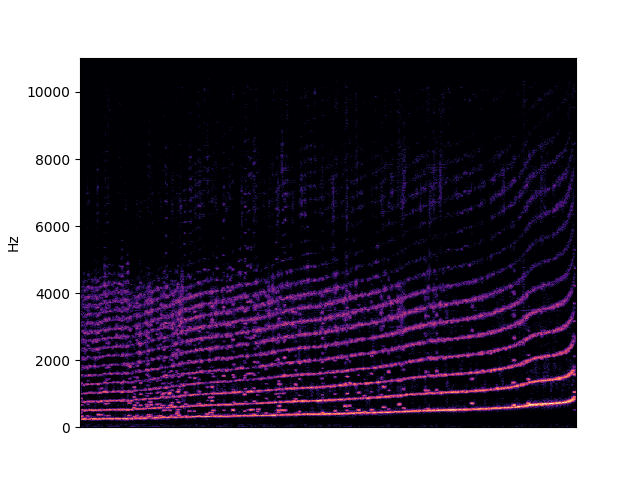 |
| fundamental in singing | |
|---|---|
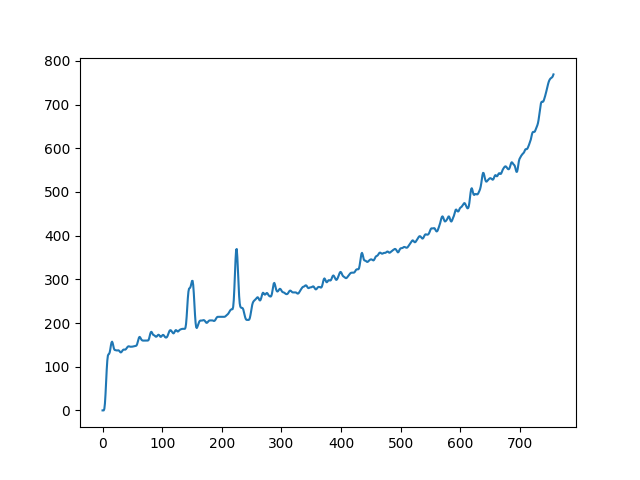 |
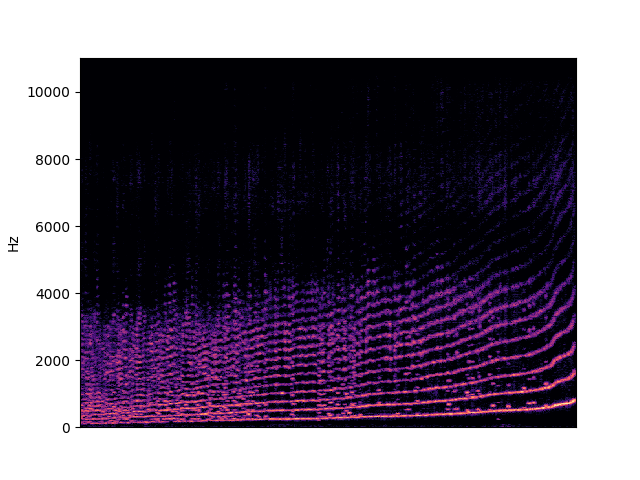 |
| centroid in singing | |
|---|---|
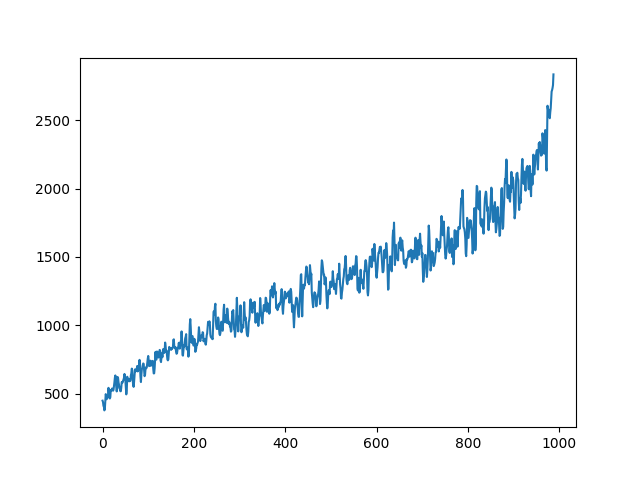 |
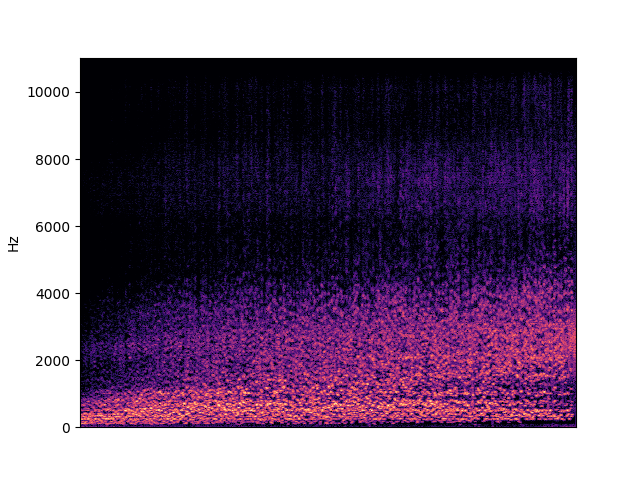 |
| fundamental in trumpet | |
|---|---|
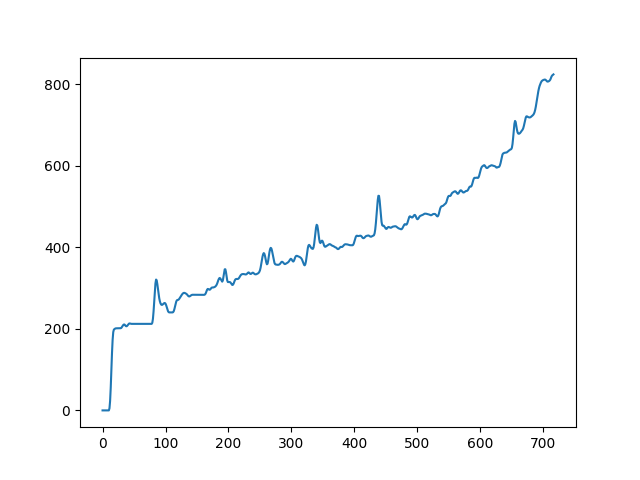 |
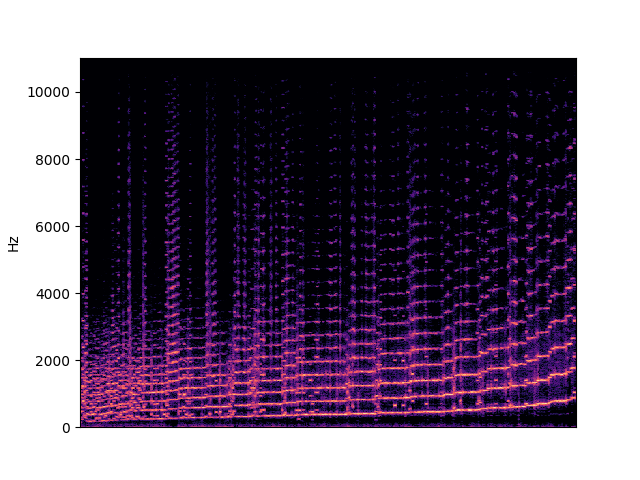 |
| centroid in viola | |
|---|---|
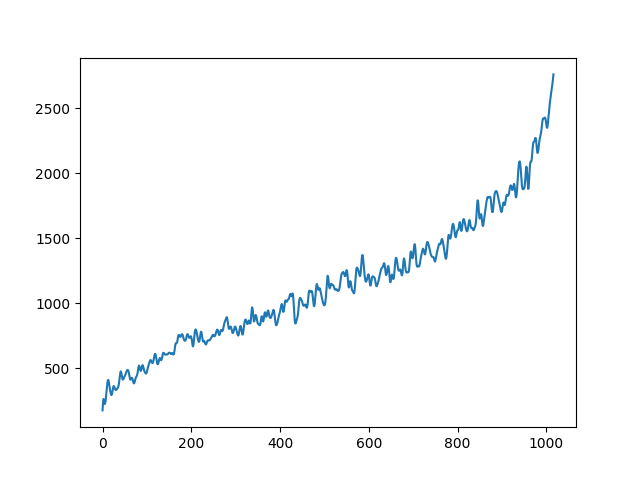 |
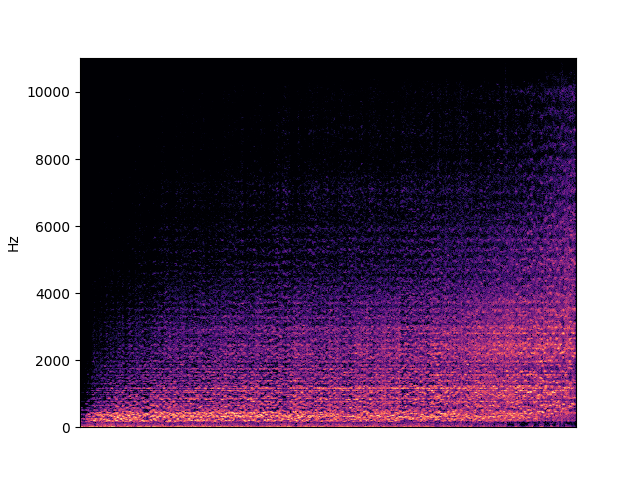 |
| bandwidth in violin | |
|---|---|
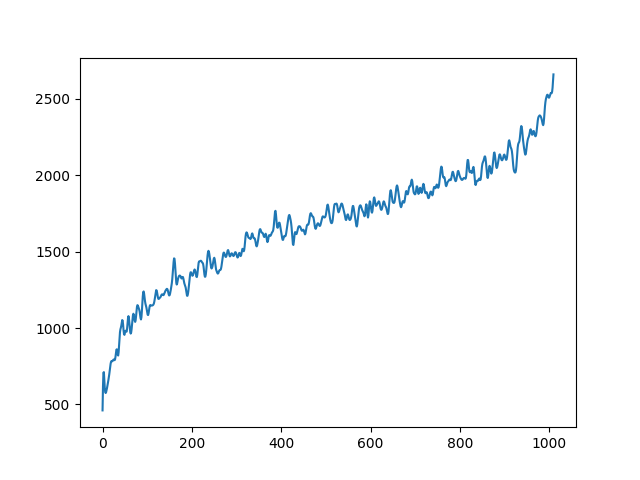 |
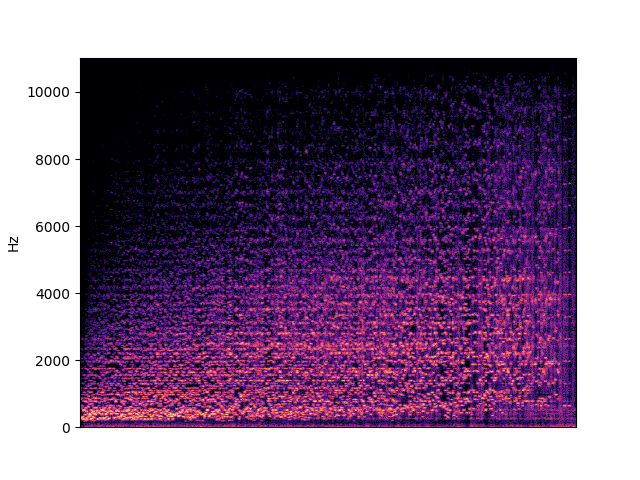 |
| centroid in violin | |
|---|---|
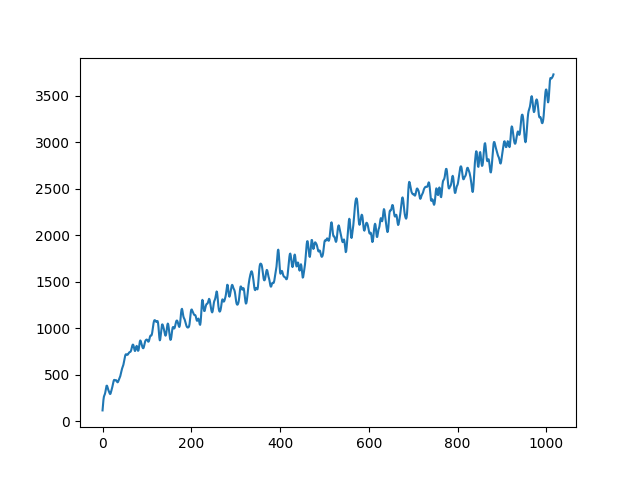 |
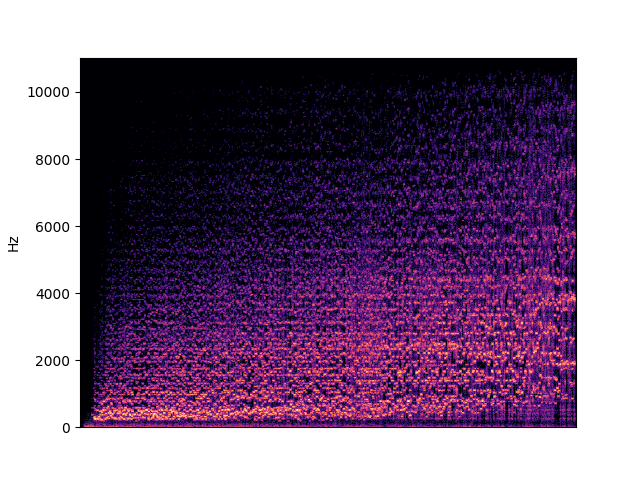 |
| fundamental in violin | |
|---|---|
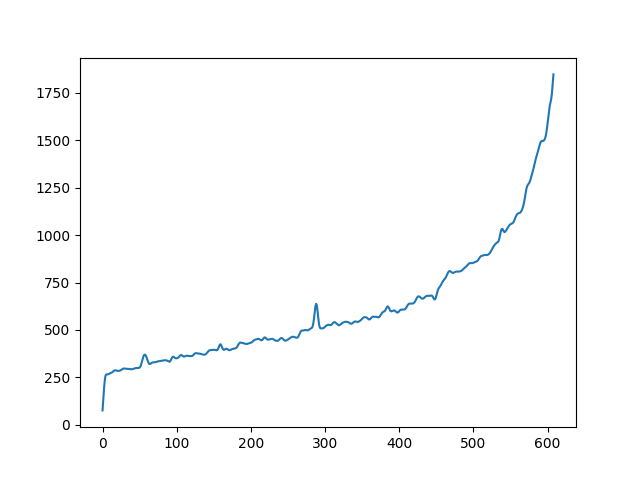 |
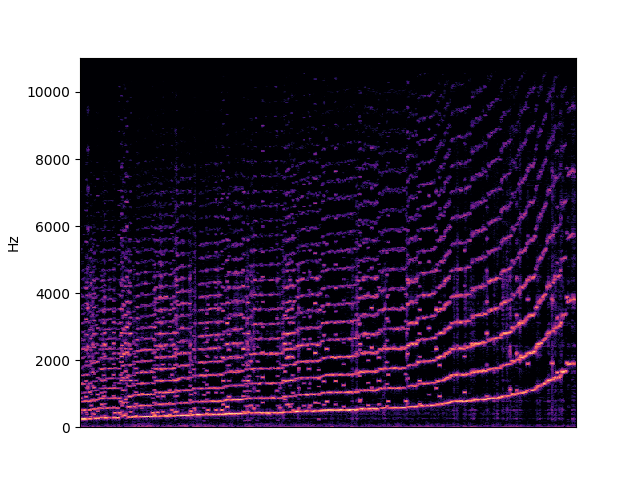 |
Timbre transfer
A model is trained on a target timbre, we input performance excerpts from other sources (unseen during training) and transfer them to the learned target timbre.
| instruments | source | target |
|---|---|---|
| clarinet → trumpet | ||
| clarinet → violin | ||
| horn → cello | ||
| horn → singing | ||
| oboe → viola | ||
| saxophone → cello | ||
| saxophone → horn | ||
| singing → violin | ||
| trumpet → clarinet | ||
| trumpet → singing |
Voice-driven sound synthesis
Besides converting singing voice into an instrument sound, we also consider inputting non-singing human voice. We take some samples from the VocalSketch database, these were crowd-sourced in uncontrolled recording conditions by asking participants to immitate some diverse targets with their voice. Such concepts would be hardly described into musical terms, however they are rather intuitively expressed by vocal imitation. This can be a new mean to drive a sound synthesis model, which do not require any particular knowledge for interaction. The first sample is a raw vocal imitation and the second a transfer to an instrument timbre. Concept refers to the text descriptions in VocalSketch that were given to imitate.
| concept → instrument | input | transfer |
|---|---|---|
| aliendiscovery → viola | ||
| banjo → cello | ||
| bongos → horn | ||
| cashregister → clarinet | ||
| cat → clarinet | ||
| crow → viola | ||
| darkattackbass → horn | ||
| feedback → violin |
Test set reconstructions
The models are trained on recording segments of about 1.5 second, we show some examples from the test set of each timbre domain and the corresponding VQ-VAE reconstruction. The first sample for each is an input and the second is the model reconstruction.
| instrument | input | reconstruction |
|---|---|---|
| basson | ||
| cello | ||
| clarinet | ||
| double-bass | ||
| flute | ||
| horn | ||
| oboe | ||
| trumpet | ||
| viola | ||
| violin | ||
| singing |