Additional materials for the submission to ICMC 2020.
View the Project on GitHub adrienchaton/neural_granular_synthesis
This page is under construction, sound and video examples are being added for the reviewing process. Stay tuned during that period and after, more experiments may be uploaded !
We recommend viewing in Chrome browser since the page rendering and audio playback may differ depending on other browsers.
In the left, a granular synthesis space is formed by analysing a library of audio grains, scattered as (+), with acoustic descriptors. These dimensions allow for visualization and control of the synthesis. A free-synthesis path can be drawn or a target criterion can be formed by analysing the grain series of an other signal (o). Grains from the library can be then selected by matching these targets with respect to acoustic descriptor values.
Some limitations arise in this process. Amongst others, the acoustic descriptors are not invertible so it is not possible to synthesize from them, besides the scattered library grain coordinates. The quality of the analysis is bound by the choice and design of acoustic descriptors, which only account for local audio similarities. Thus this space does not organize the longer temporal structure of audio events such as notes or drum hits, which cannot be generated without features extracted from an other corresponding target signal.
In the right, developping a raw waveform Variational Auto-Encoder to learn a grain latent space, we alleviate some of these limitations and enable new generative processes based on concepts of granular sound synthesis. Its learned analysis dimensions are continuously invertible to the signal domain. We can thus synthesize along any path, without need to store the grain library after the training. An other sound sample can be auto-encoded, to perform resynthesis, with some possible additional user controls to condition the decoder generation. On top of this grain-level representation, we can efficiently train a recurrent embedding on contiguous grain series to learn meaningful temporal paths within the latent grain space. As a result, the model can sample structured audio envents such as note and drum hits, as well as morph their features.
Neural Granular Sound Synthesis
This figure details the complete Variational Auto-Encoder (VAE) model. The lower VAE encodes grain series into latent series, which are fed to the subtractive noise synthesis decoder. It can be conditionned with concatenation of one-hot user labels. The decoded grain series are overlap-add into a waveform. A second recurrent VAE can be trained on contiguous series of latent features, to learn structured paths in the grain space. Performing this temporal modeling at the down-sampled grain level efficiently accounts for the longer-term relationships while the bottom VAE ensures the quality of the local grain features. Waveform synthesis is optimized with a multi-scale spectrogram reconstruction objective, to account for both transient and harmonic sound features.
2D visualization (with Principale Component Analysis, PCA) of a learned grain space over individual pitched notes of orchestral instruments (from SOL dataset and subsequent coloring). Grains can be synthesized from any latent position, at or besides these points of the database latent scatter.
By using this two-level audio modeling, we can generate structured audio events such as musical notes or drum hits. In the first place, the top level embedding is sampled, a latent path is recurrently decoded. This series is fed to the bottom filtering noise decoder which outputs the corresponding waveform.
Generation from the temporal embedding
By performing interpolations in the top level embedding, we can transition in between features at the scale of structured audio events. For instance, generating successive latent grain paths that correspond to evolving drum enveloppes, from snapped to more sustained/resonating.
Resulting interactions in Neural Granular Sound Synthesis. In the left, structured latent paths can be sampled from the higher temporal embedding. In the middle, we can draw and freely synthesize along any latent trajectory. In the right, we can encode an other target signal and resynthesize it.
Summary of generative granular interactions
All sound/video examples are raw outputs of the models (besides inputs for the reconstructions and resynthesis), without any kind of audio effect/processing added.
Data reconstructions are performed by auto-encoding a database sample. Each pair of sounds is the input followed with the model reconstruction. In that case, the best accuracy and audio fidelity is desired, assessing the performance of the trained model in the reconstruction objective. Following are some violin note reconstructions from Studio-On-Line.
Following are some reconstructions across the SOL orchestra in ordinario.
Following are some drum hit reconstructions in the 8 Drums dataset.
Using a model with temporal embedding, trained on the 8 classes of the 8 Drums dataset, we can sample drum hits. In this order, a crash, a kick, a ride, a snare and a tom.
Using such a model trained on SOL dataset, we can sample instrumental notes. In this order violin, cello, clarinet, french-horn and piano.
Variable length free-synthesis trajectories can be drawn accross the latent space, continuously inverting to grains and waveform. For instance, linear interpolations in the latent grain space of a model trained in SOL.
Latent trajectories may as well be looped, such as a forward-backward linear interpolation, where the step size can be randomized since the model can continuously synthesize along this latent segment. Here applied to strings in SOL or to the drum sounds in the 8 Drums dataset.
We can perform resynthesis by encoding an other sample and decoding its inferred latent grain features. When the target signal does not match the training data distribution of the model, only part of the source features are preserved. The overall synthesis extrapolates the input signal in the style of the training data domain. The following audio files contain diverse input sounds and their resynthesis by a neural granular synthesis model. In the order source/resynthesis: laught to violin, pizzicato to drums, clarinet to violin, violin to cat and clarinet to cat.
Each audio event sampled from the temporal embedding is represented as a single feature point. When interpolating in between two points, we can generate the corresponding latent grain paths which result in waveforms with evolving structure. For instance, we applied this to drums in order to get varying enveloppes. Each audio file is the first decoded embedding point, an intermediate point and the other end point. We set the intermediate sample half-way in the embedding interpolation.
With GPU support, for instance a sufficient dedicated laptop chip or an external thunderbolt hardware, the models can be ran in real-time. In order to apply trained models to these different generative tasks, we currently work on some prototype interfaces based on a Python OSC server controlled from a MaxMsp patch.
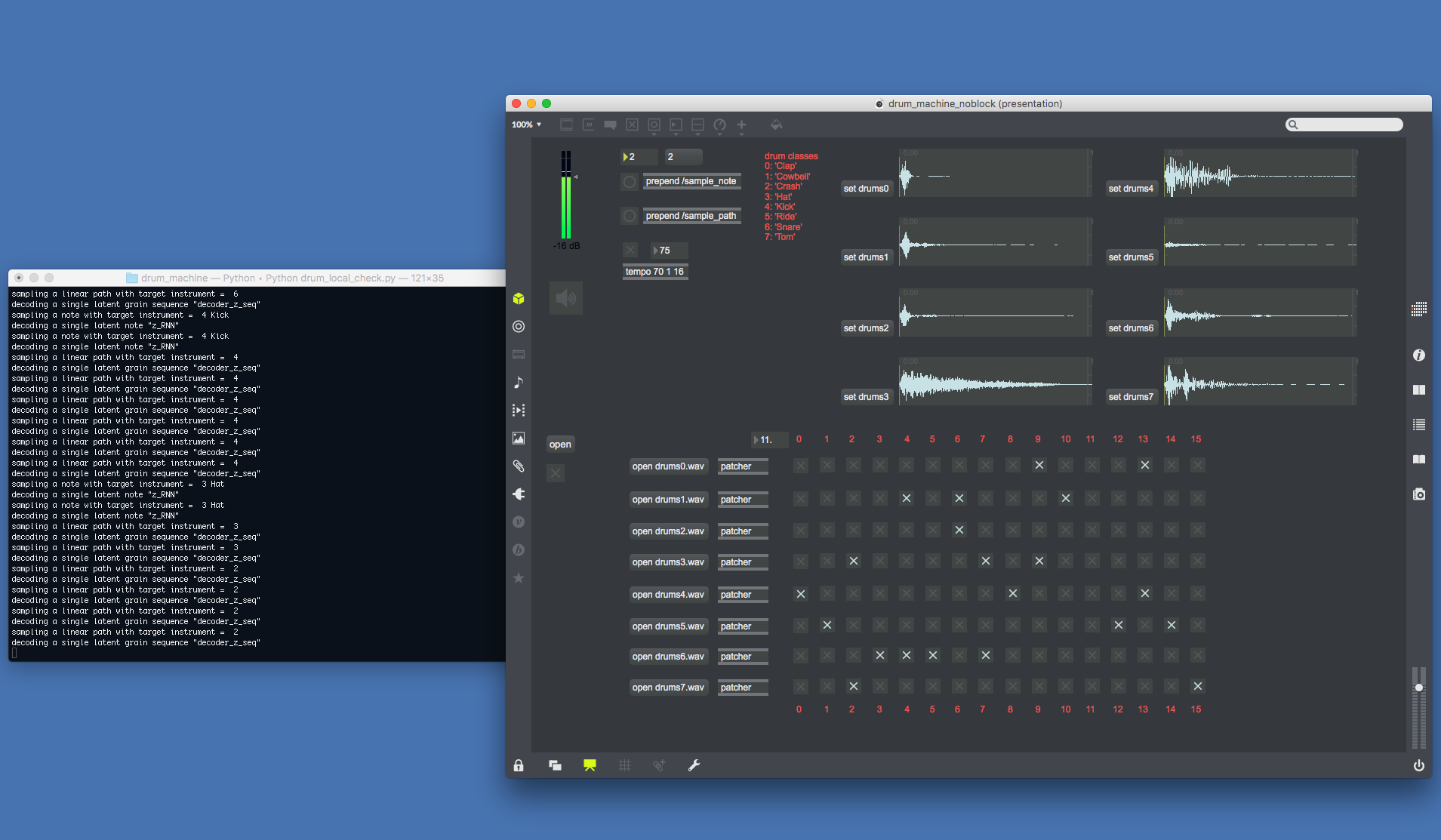
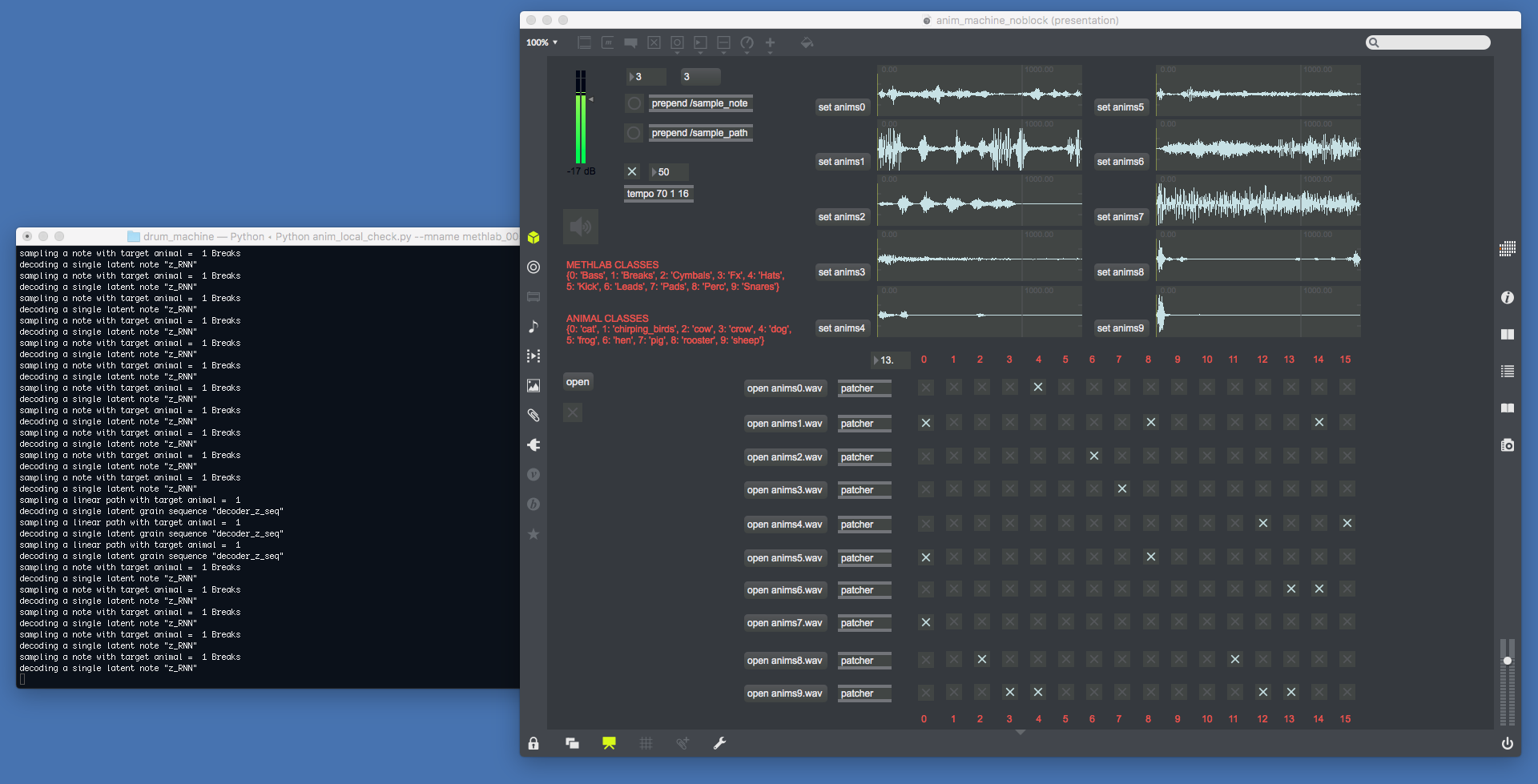
Using a model with sequential embedding and conditioning trained over the 8 Drums dataset classes, we can sample structured one-shot audio clips for each of the drum classes. Since its embedding is continuous, we can explore a great diversity of sounds. Moreover, we can alternatively sample random paths to explore other spectro-temporal dynamics. Once the samples are chosen, they can be played-back in realtime with a 8-track step sequencer, without having an actual sample library but only a generative neural network to write the buffers.
The videos are made while running the model on a MacbookPro Retina 2015 (without GPU), some latency can be seen when sampling and writing the buffers. Such latency is however low and given a GPU it could be sampled in real-time by the step sequencer rather than played-back.
The upper integer box selects the drum condition sent to the model. The trigger to the message sample_note generates a drum hit from the recurrent embedding. The trigger to the message sample_path draws a randomized linear path in the grain space, of same length as the embedding sample. This can be seen in the python console on the left side, answering to the messages sent through OSC. While the step sequencer loops, it is possible to resample some drum sounds that overwrite the previous buffer.
For this one, a model trained on 10 classes of a Methlab sample pack is used with a corresponding 10-track step sequencer. Classes are Bass, Break, Cymbal, Fx, Hat, Kick, Lead, Pad, Perc, Snare. We use a restricted set of 260 sound samples collected from their online music competitions. The process is similar to the previous video, but the classes of sounds are more ambiguous and not restricted to one-shot samples (e.g. loops).
Example of loop generated with this step sequencer and model:
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}